“天才少女”罗福莉,终于露面了。
去年 12 月,业界就传闻雷军千万年薪挖人,后来一直没有明朗消息。直到上个月才官宣罗福莉领导小米 Mimo 大模型团队,有业内人士猜测,也许是由于竞业条件限制。
不论如何,在昨天的2025小米“人车家全生态”合作伙伴大会上,罗福莉贡献了自己的首次主题演讲。

她没有把时间花在吹嘘MiMo模型,而是提出了有趣的问题:今天我们所走的这条大模型之路,是不是走反了?
她用了一个极为精妙的类比:生物演化。
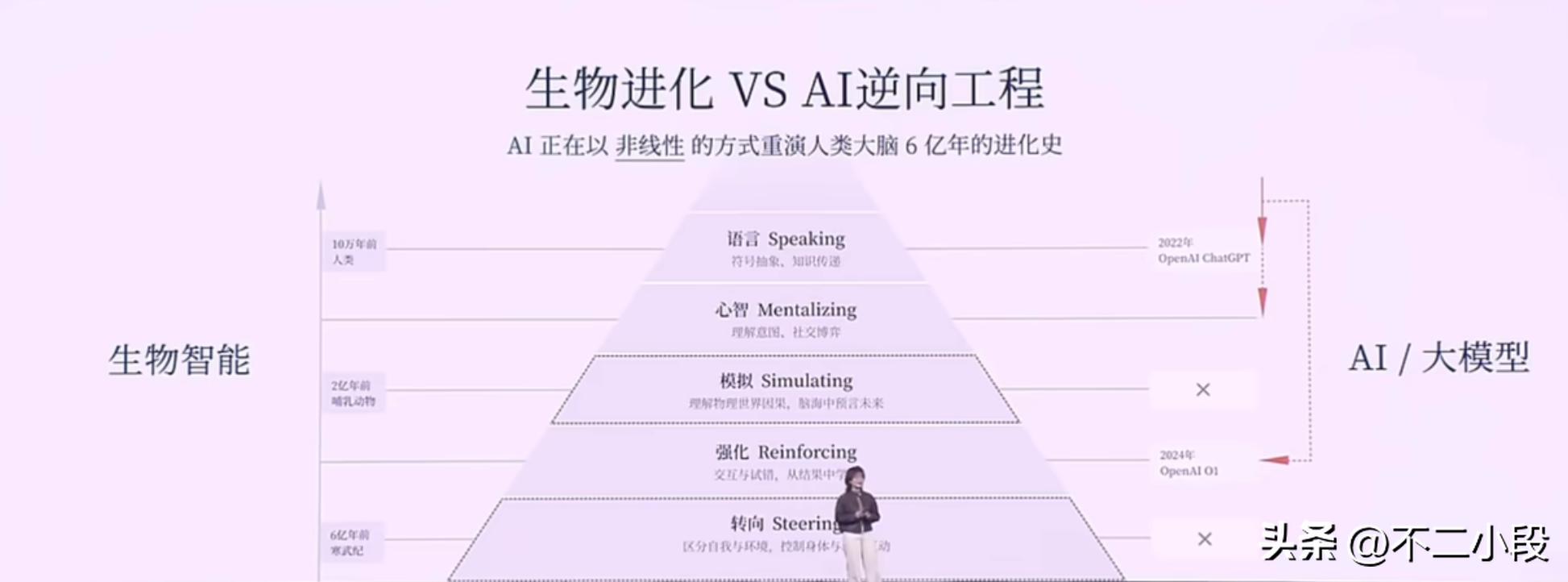
回溯6亿年的生命长河,智能的诞生遵循着一条严密的逻辑。
生命体首先要学会的,是控制自己的身体,与物理环境进行交互,这是生存的根本。然后,进化出奖惩机制,比如多巴胺系统,通过强化学习优化生存策略。再之后,才是在大脑中模拟未来、进行规划的能力。
最后,也是最晚出现的,才是语言——这个高度抽象的符号系统,人类智能的冠冕。
这个顺序是:行动 → 思考 → 语言。从物理世界到内心世界,再到符号世界。
而今天的大模型,走的却是一条完全相反的路:语言 → 思考 → (试图)行动。
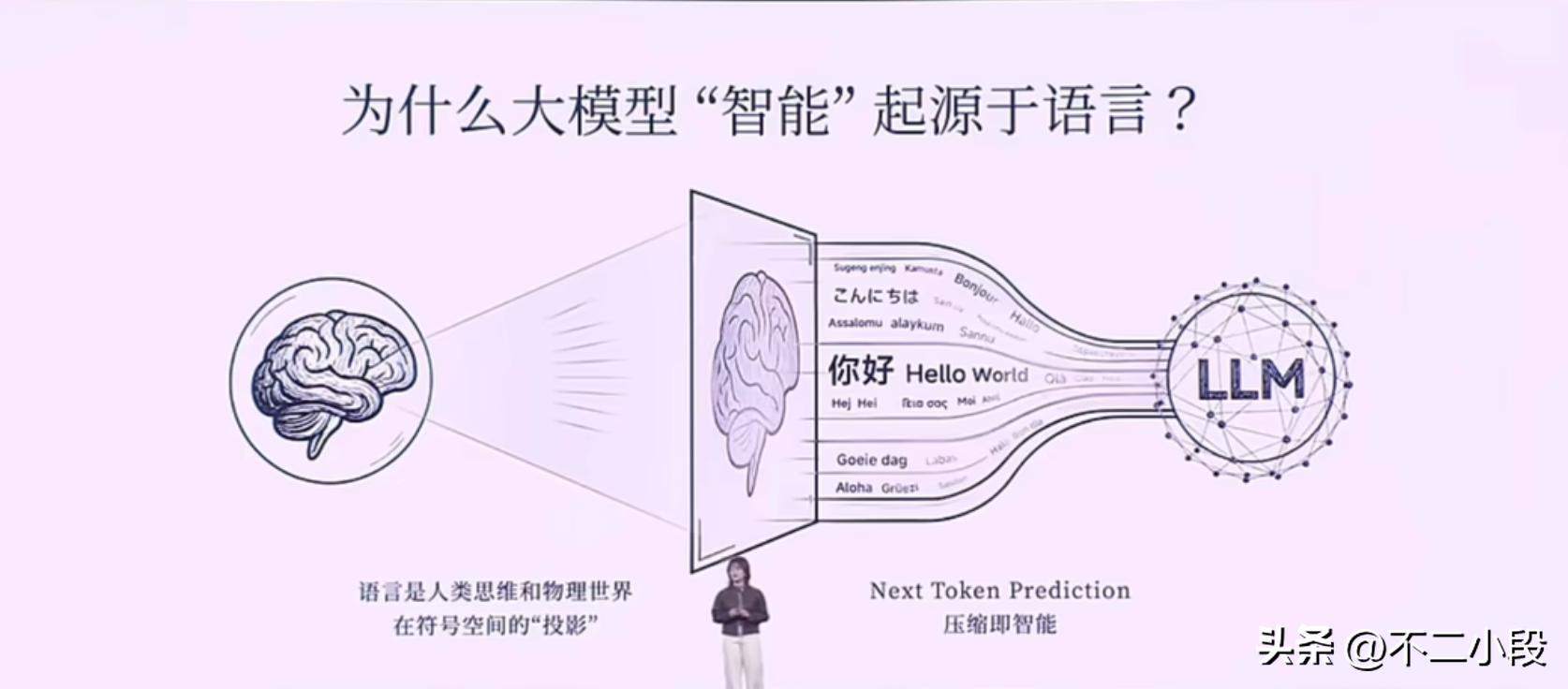
模型从海量的文本数据中,通过“下一个词预测”这样看似简单的范式,暴力破解了语言这个人类智慧的顶层建筑。
罗福莉将这个过程描述为对人类知识的“有损压缩”。
当一个模型试图将Loss降到无限趋近于零时,它不仅仅是在拟合统计规律,更是在重构人类数十亿年积累下来的,关于世界的认知在文本空间里的投影。
这是一个惊人的成就,也是一条聪明的“捷径”。
大模型通过算力的暴力美学,直接攻克了智能金字塔的塔尖。它学会了人类的说话方式,学会了模仿莎士比亚写作,甚至能通过奥数竞赛。它看起来无所不知,因为它解码了人类“智能的结果”。
但问题也恰恰出在这里。它只学会了结果,却跳过了产生这个结果的全部过程。
它拥有一个完美的语言外壳,但这个外壳之下,是空的。它没有锚定现实世界的物理模型。它知道“引力”这个词经常和“苹果”、“下落”一起出现,但它并不真正理解重力的含义。所以它会一本正经地胡说八道,产生匪夷所思的幻觉。
这就解释了为什么当今最强大的AI,能帮你写代码、写诗歌,但你依然不放心让它帮你煮个鸡蛋。因为它从未“活”在我们的世界里,它只是一个无比博学的“阅读者”。
这个观点很有趣,也值得我专门写一篇文章浅做笔记。
因为她清晰地指出了这条“AI 倒叙”路径的局限性,并且把小米MiMo模型的技术选择,阐释为对这条路径的一次修正,或者说,一次补课。
她说,真正的智能,不是在文本里“读”出来的,而是在交互里“活”出来的。
这句话,几乎可以看作是小米做大模型的一个重要角度。
当行业大部分参与者还在语言的竞技场里内卷,比拼谁的模型更能说会道时,小米选择了一个更长远的方向:让AI从语言走向物理世界。
他们认为,AI进化的下一个起点,必然是一个可以和真实环境产生交互的物理模型。
至于MiMo-V2-Flash这个模型。罗福莉提到了三个核心问题。

第一个问题:Agent的高效沟通语言是什么?
答案是代码和工具调用。如果AI要与物理世界互动,它就不能只停留在聊天。它需要操作软件、调用API、控制硬件。语言是人与人沟通的桥梁,而代码和工具,则是AI与数字世界乃至物理世界沟通的桥梁。
所以,MiMo-V2-Flash不惜代价地强化了代码和工具调用能力,让它成为一个高效的“执行者”,而不仅仅是一个“对话者”。
第二个问题:如何提升Agent之间的协作带宽?
单一Agent的能力是有限的,未来的复杂任务必然由多个Agent协作完成。但目前Agent之间的沟通,很多时候还是通过自然语言,带宽极低,效率堪忧。
要提升带宽,就需要一个推理效率极高的模型作为底层支持。这就引出了MiMo在模型结构上的取舍。
他们没有去追逐那些学术上看起来很酷炫、但工程上很复杂的注意力机制。反而选择了看似简单的滑动窗口注意力,因为它有一个巨大的优点:KV Cache是固定的,能很好地适配现有的推理加速框架。实用主义压倒了一切。
同时,他们挖掘了MTP的潜力,在训练、微调和推理阶段都用上了,最终实现了2-3倍的实际推理加速。
最终的结果是,一个激活参数仅15B的模型,在性能上追平甚至超过了参数量是它2到3倍的对手,同时推理成本极低,速度极快。
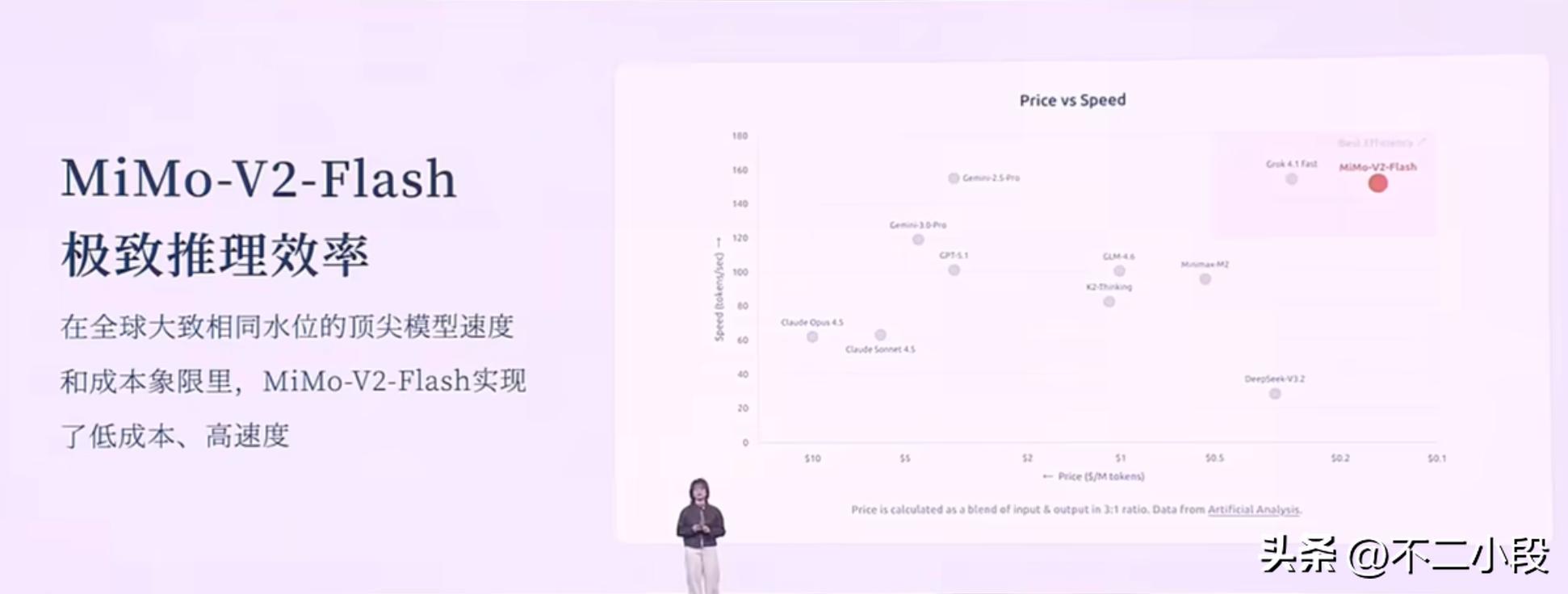
在全球顶尖模型的速度与成本象限图里,MiMo-V2-Flash处在右上角的“低成本、高速度”区间。
第三个问题:如何激发后训练的潜力?
当预训练的Scaling Law边际效应递减,真正的能力分水岭就转移到了后训练阶段,也就是强化学习等环节。但强化学习训练是出了名的不稳定,很容易把模型“训傻”。为了解决这个问题,他们提出了一种叫MOPD的范式。
这个方法的核心在于,让一个学生模型自己去生成内容,然后请多个不同领域的“专家模型”来给这些内容进行“token-level”的稠密打分,再用这些信号来指导学生模型学习。
这种方式就像一个学徒在练习,身边围了一群不同工种的老师傅,随时对他每一步操作进行点评,学习效率极高。罗福莉提到,他们甚至发现学生模型很快就能超越老师,然后又可以把这个更强的学生变成新的老师,进行自我迭代。这为模型的持续进化提供了一个高效且稳定的路径。
把这三点串起来,小米的路线图就非常清晰了:以一个推理极致高效的基座模型为核心,赋予它超强的代码和工具调用能力,再通过高效稳定的后训练范式让它持续进化,最终的目标,是构建一个能够“完成任务”而不仅仅是“回答问题”的智能体系统。
这个系统,将不再是一个语言模拟器,而是一个与我们的世界共存的智能体。

更有意思的是,罗福莉在演讲中坦承,她所说的“物理世界导向是通往AGI的关键”是一个“非共识”。她提到了包括Ilya Sutskever在内的一些顶尖研究者,依然坚信在纯粹的语言空间里就能实现AGI。
她没有去辩驳,而是做了一件很酷的事情:她去问了MiMo-V2-Flash自己。
她问模型:你怎么解读“智能必须根植于物理世界,强调多模态和真实世界交互才是通往AGI的关键”这个观点?

模型的回答是:这是一个核心且深刻的观点。智能要根植于“存在”,而非“符号”。符号系统只能进行模式匹配和概率预测,而真正的智能必须嵌入到一个具身化的环境中,通过与物理世界持续交互,才能涌现出更强的能力。
这个回答令人玩味。一个由符号训练出来的模型,自己“涌现”出了对符号局限性的认知。这本身就构成了一种奇妙的印证。
在演讲的最后,罗福莉谈到了真正的护城河。
她说,算力和数据并非最终的护城河,真正的护城河是“科学的研究文化和方法”,是将未知问题转化成模型优势,并最终结合成可用产品的能力。
从2020年,中国的开源模型与世界顶尖的闭源模型还有至少三年的代差,到今天,这个差距被缩短到只有数月。这个速度是惊人的。
罗福莉将开源的价值定义为“分布式的技术加速主义”,是确保AGI普惠化、确保人类智慧共同进化的唯一路径。
这或许可以解释,为什么小米会选择将模型直接开源。这不仅仅是一种姿态,更是一种信念。信念就是,在通往AGI的崎岖道路上,封闭的、各自为战的探索,远不如开放的、集思广益的共同进化来得更快、也更安全。




发表评论 取消回复