大多数团队搭完RAG系统后,跑一下评测,发现准确率卡在60%左右——能回答一些问题,但漏检、幻觉、答非所问的比例高得让人没法上线。然后开始"玄学调参":换个Embedding模型试一下、调一下Chunk Size试一下、加个Reranker试一下,每次提升两三个百分点,最后勉强到70%就觉得到头了。
问题不在于调参,而在于没有把RAG当成一个系统工程来做。60%到85%的跃迁,不是某个单一环节的优化,而是从数据处理到检索策略到生成控制的全链路系统性提升。
这篇文章从架构师视角,把RAG准确率提升拆成五个可量化、可独立优化的环节,每个环节给出具体的工程方案和效果预期。

先搞清楚:RAG的60%到底差在哪?
在动手优化之前,必须先做归因分析。60%的准确率意味着40%的问题没有正确回答,但这40%的"错"各有不同:
检索阶段的损失(通常占20-25%):
- 相关文档没有被召回(Recall不足)
- 召回了但排名太靠后(Precision不足)
- 问题表述和文档表述之间存在语义鸿沟
生成阶段的损失(通常占10-15%):
- 检索到了正确文档,但LLM没有从中提取正确答案
- 多个文档之间信息矛盾,LLM选错了
- 上下文窗口放了太多无关内容,干扰了LLM判断
数据质量的损失(通常占5-10%):
- 知识库本身有错误或过时信息
- 文档分块切掉了关键上下文
- 表格、代码、图片等非纯文本内容丢失了结构

经验法则:先做诊断再动手。用一个200-500条的标注测试集,按"未召回/召回但未命中/命中但生成错误"三类统计错误分布,找到最大的瓶颈再集中优化。
第一关:分块策略——切错了一切白搭
分块(Chunking)是RAG中最被低估的环节。分块策略直接决定了"检索粒度"和"上下文完整性"之间的平衡。
固定长度分块的陷阱
最简单的做法是按固定token数切分(如512 tokens + 50 tokens重叠)。问题在于:语义边界被随机切断。
一段关于"分布式事务的三种补偿模式"的论述,可能在第300个token处被切成两半,前半段在A chunk里讲了TCC模式,后半段在B chunk里讲了Saga模式。用户问"Saga模式怎么实现",系统只召回了后半段,丢失了前文的定义和上下文。
语义感知分块
更好的做法是按语义边界分块:
- 段落/章节感知:利用文档自身的标题层级和段落结构,以小节为单位分块
- 语义相似度切分:用Embedding模型计算相邻句子的语义相似度,在相似度骤降处切分(意味着话题切换)
- 递归分块:先按大节切,超长的再按段落切,再超长的按句子切——保持每一块的语义完整性
分块大小的工程经验值
- 通用QA场景:256-512 tokens,重叠50-100 tokens
- 技术文档/法律文本:512-1024 tokens,需要保留完整论述
- FAQ/短问答:128-256 tokens,精确匹配优先
- 代码片段:按函数/类为单位,不按token数切
关键指标:分块后每个chunk的"主题纯度"——一个chunk应该只包含一个主题的完整论述。如果一个chunk里混了三个不相关话题,说明分块粒度太粗。
Parent-Child Chunking
一种兼顾精确匹配和上下文完整性的策略:
- Child chunks(小块):128-256 tokens,用于检索匹配——小块更容易命中
- Parent chunks(大块):512-1024 tokens,用于送入LLM生成——提供完整上下文
检索时用child chunk匹配,命中后把对应的parent chunk作为上下文送给LLM。这样既保证了检索精度,又保证了生成质量。
第二关:Embedding——向量模型选对了吗?

Embedding模型决定了文档和查询是否能在向量空间中"对齐"。选错模型,后面所有优化都是在补漏。
模型选型决策矩阵
- 通用英文场景:text-embedding-3-large(OpenAI)或 bge-large-en-v1.5
- 中文场景:bge-m3(BAAI)或 text2vec-large-chinese
- 多语言混合:bge-m3支持100+语言,是目前性价比最高的选择
- 长文本:jina-embeddings-v3支持8K tokens输入,避免长文档截断
Embedding微调:花10倍的力气换20%的提升?
在垂直领域(医疗、法律、金融),通用Embedding模型的表现确实有天花板。微调可以带来显著提升,但投入产出比需要评估:
值得微调的信号:
- 领域术语密度高(如医学缩写、法律术语)
- 通用模型的MRR@10低于0.6
- 有足够的标注数据(至少500对query-document相关性标注)
微调方法:
- 对比学习微调:用领域数据构造正负样本对,训练模型拉近正样本、推远负样本
- 指令微调:在embedding时加入任务指令(如"检索法律条款"),让模型理解检索意图
- Matryoshka表示学习:训练时同时优化不同维度的embedding,部署时可以按需截断以降低计算成本
混合检索:向量+关键词双保险
纯向量检索的弱点是精确匹配——用户搜"RFC 7231",向量检索可能返回所有关于HTTP协议的文档,但不保证精确命中引用了RFC 7231的那个chunk。
混合检索(Hybrid Search)是当前最佳实践:
最终得分 = α × 向量相似度 + (1-α) × BM25关键词得分
- α通常取0.6-0.8(向量为主,关键词为辅)
- BM25对精确术语、编号、人名等精确匹配非常有效
- 向量检索负责语义理解,BM25负责字面匹配,互补性很强
第三关:查询理解——用户问的和系统理解的不是一回事
这一关是最容易被忽略的,但往往是从70%到80%的关键跳板。
问题一:Query太短太模糊
用户问"这个怎么用?"——"这个"是什么?"怎么用"是在问安装、配置、还是API调用?系统拿到这个query去检索,大概率返回一堆不相关的文档。
解决方案:查询扩展(Query Expansion)
在检索前,用LLM对用户query进行改写和扩展:
原始query: "这个怎么用"
→ LLM改写: "XXX框架的安装配置和基本使用方法"
→ 同时生成2-3个变体query并行检索,合并结果
具体技术:
- Multi-Query:让LLM生成3-5个不同角度的改写版本,分别检索后合并去重
- HyDE(Hypothetical Document Embeddings):让LLM先生成一个"假设性答案",用这个答案的embedding去检索——因为假设性答案和真实文档在向量空间中更接近
问题二:复杂问题需要分解
用户问"对比一下React和ReAct两种Agent架构的优缺点"——这是一个需要从多个维度检索信息的复合问题。
解决方案:查询分解(Query Decomposition)
原始query: "对比React和ReAct的优缺点"
→ 分解为:
1. "React Agent架构的设计原理和优势"
2. "ReAct Agent架构的设计原理和优势"
3. "React和ReAct的区别和适用场景"
→ 分别检索 → 合并结果 → 综合生成
问题三:用户query和文档表述之间的语义鸿沟
用户问"怎么让系统响应更快",文档里写的是"通过异步非阻塞I/O降低P99延迟"——语义相同,表述完全不同。
解决方案:
- 意图识别层:先用LLM判断query属于什么类型的问题(事实查询/对比分析/操作指南/概念解释),不同类型走不同的检索策略
- 文档增强:在分块阶段为每个chunk生成synthetic query(合成问答对),用这些query做索引,匹配度更高
第四关:重排——检索到了但排名不对
向量检索返回的Top-K结果,相关性排序往往是粗糙的。Reranker的作用是用更精确的模型对检索结果重新排序。
为什么向量检索排不准?
向量检索用的是双塔模型(Bi-Encoder):query和document分别编码,在向量空间中算余弦相似度。这种架构牺牲了精度换取速度——query和document在编码时看不到对方,无法做细粒度的交互计算。
Reranker用的是交叉编码器(Cross-Encoder):把query和document拼在一起输入模型,让它看到两者的逐词交互。精度高得多,但计算量也大得多,所以只能对Top-K候选做重排,不能全库检索。
Reranker选型
- Cohere Rerank:API服务,开箱即用,支持多语言
- bge-reranker-v2-m3:开源,中文表现好,可本地部署
- jina-reranker-v2:支持长文本,多语言
- ColBERT:延迟检索架构,token级别的细粒度匹配,兼顾速度和精度
重排的投入产出
在实测中,加一个Reranker通常能提升5-10个百分点的准确率。这是RAG调优中投入产出比最高的单一优化。
推荐配置:向量检索Top-50 → Reranker重排 → 取Top-5送入LLM。
第五关:生成控制——检索到了但答不对
到了生成阶段,LLM已经拿到了相关文档作为上下文。但"给了正确答案不代表能答对"——这是很多团队的盲区。
上下文窗口管理
把Top-5的chunk全部塞进prompt,总token数可能达到3000-5000。过多的上下文会带来两个问题:
- Lost in the Middle:LLM对上下文中间位置的信息关注度低于开头和结尾
- 无关信息干扰:即使只有一小段不相关的内容,也可能误导LLM的判断
解决方案:
- 对Reranker输出的Top-K结果,再做一次去重和去噪:去掉信息重复度超过80%的chunk,去掉与query相关度低于阈值的chunk
- 最终送入LLM的上下文控制在2000-3000 tokens
- 把最相关的chunk放在prompt的最前面(利用Lost in the Middle效应)
Prompt Engineering for RAG
RAG场景的prompt设计和通用对话完全不同:
你是一个精确的信息检索助手。根据以下参考资料回答问题。
规则:
1. 只使用参考资料中的信息回答,不要使用你的先验知识
2. 如果参考资料中没有足够信息,明确说"根据现有资料无法确定"
3. 引用具体来源,格式:[来源X]
4. 如果多个来源信息矛盾,指出矛盾并给出各自的立场
参考资料:
[1] {chunk_1}
[2] {chunk_2}
[3] {chunk_3}
问题:{query}
关键点:
- 强制引用:让LLM标注每个回答来自哪个chunk,便于溯源和验证
- 拒绝回答机制:当检索到的内容确实无法回答问题时,允许LLM说"不知道"——这比硬答一个错误答案好得多
- 矛盾处理:多个来源矛盾时不要硬选一个,而是呈现各方观点
答案验证层
在生成之后加一个验证步骤:
- 事实核查:用LLM检查生成的答案是否确实被参考资料支持
- 幻觉检测:检查答案中是否有参考资料中没有的信息
- 完整性检查:检查问题的所有子问题是否都被回答了
不通过验证的答案要么重新生成,要么降级为"部分回答"。
评估体系:没有度量就没有优化
评估指标框架
RAG系统的评估需要分层进行:
检索质量指标:
- Recall@K:Top-K结果中包含正确文档的比例(目标>90%)
- MRR(Mean Reciprocal Rank):正确文档的排名倒数的均值(目标>0.7)
- NDCG@5:考虑排名位置的检索质量(目标>0.75)
生成质量指标:
- Faithfulness:答案被参考资料支持的比例(目标>0.9)
- Answer Relevance:答案与问题的相关度(目标>0.85)
- Context Precision:参考资料中真正有用的比例(目标>0.8)
端到端指标:
- Answer Correctness:最终答案的正确率(目标>85%)
RAGAS框架
[RAGAS](
https://github.com/explodinggradients/ragas)是目前最主流的RAG评估框架,它用LLM-as-Judge的方式自动评估上述指标,不需要人工标注。
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_precision
result = evaluate(
dataset=eval_dataset,
metrics=[faithfulness, answer_relevancy, context_precision],
)
print(result)
建议维护一个200-500条的标注测试集,每轮优化后都跑一遍,用数据说话而不是凭感觉。
前瞻:RAG架构的下一步演进
GraphRAG:从平面检索到知识图谱
传统RAG的向量检索本质上是"平面"的——每个chunk独立存在,chunk之间没有关系。GraphRAG把文档中的实体和关系抽取出来,构建知识图谱,检索时可以沿着关系链路做多跳推理。
用户: "张三参与的项目有哪些技术栈?"
传统RAG: 检索"张三"+"技术栈" → 可能漏掉间接关联
GraphRAG: 张三 → 参与 → 项目A → 使用 → [Spring, Kafka, Redis]
→ 参与 → 项目B → 使用 → [React, Go, PostgreSQL]
微软的GraphRAG论文已经证明,在需要跨文档推理的场景中,GraphRAG的准确率比传统RAG高15-20个百分点。
Agentic RAG:让RAG自己决定怎么检索
传统RAG是"一锤子买卖":用户问一次,系统检索一次,生成一次。Agentic RAG把RAG流程变成一个Agent工作流:
- 第一次检索后,Agent评估结果质量
- 如果结果不够好,Agent自主决定:换查询策略?扩大检索范围?分解子问题?
- 可以进行多轮检索-推理循环,直到Agent认为有足够的信息来回答
这本质上是把我们上面讲的所有优化策略(查询扩展、查询分解、多轮检索、答案验证)串成了一个自适应的Agent流程。
Self-RAG:LLM自己判断要不要检索
不是所有问题都需要检索。"1+1等于几"不需要查知识库,"公司的年假政策"才需要。Self-RAG让LLM在回答前先判断:
- 是否需要检索? → 判断当前query是否需要外部知识
- 检索结果是否有用? → 判断召回的文档是否与问题相关
- 生成的答案是否被支持? → 判断答案是否有据可依
通过引入反思token(reflection tokens),LLM可以在推理过程中自主决定检索时机和检索次数,避免了"不需要检索时强行检索"和"需要检索时没检索"的问题。
多模态RAG
当知识库不只有文本,还有表格、图片、PDF扫描件时,传统纯文本RAG就力不从心了。多模态RAG需要:
- 表格理解:将表格转为结构化表示,支持"哪个产品的Q3销量最高"这类查询
- 图片理解:用视觉模型理解图表、流程图、架构图的内容
- PDF版面分析:识别标题、正文、表格、图片的位置关系,保持文档结构
从60%到85%的调优路线图
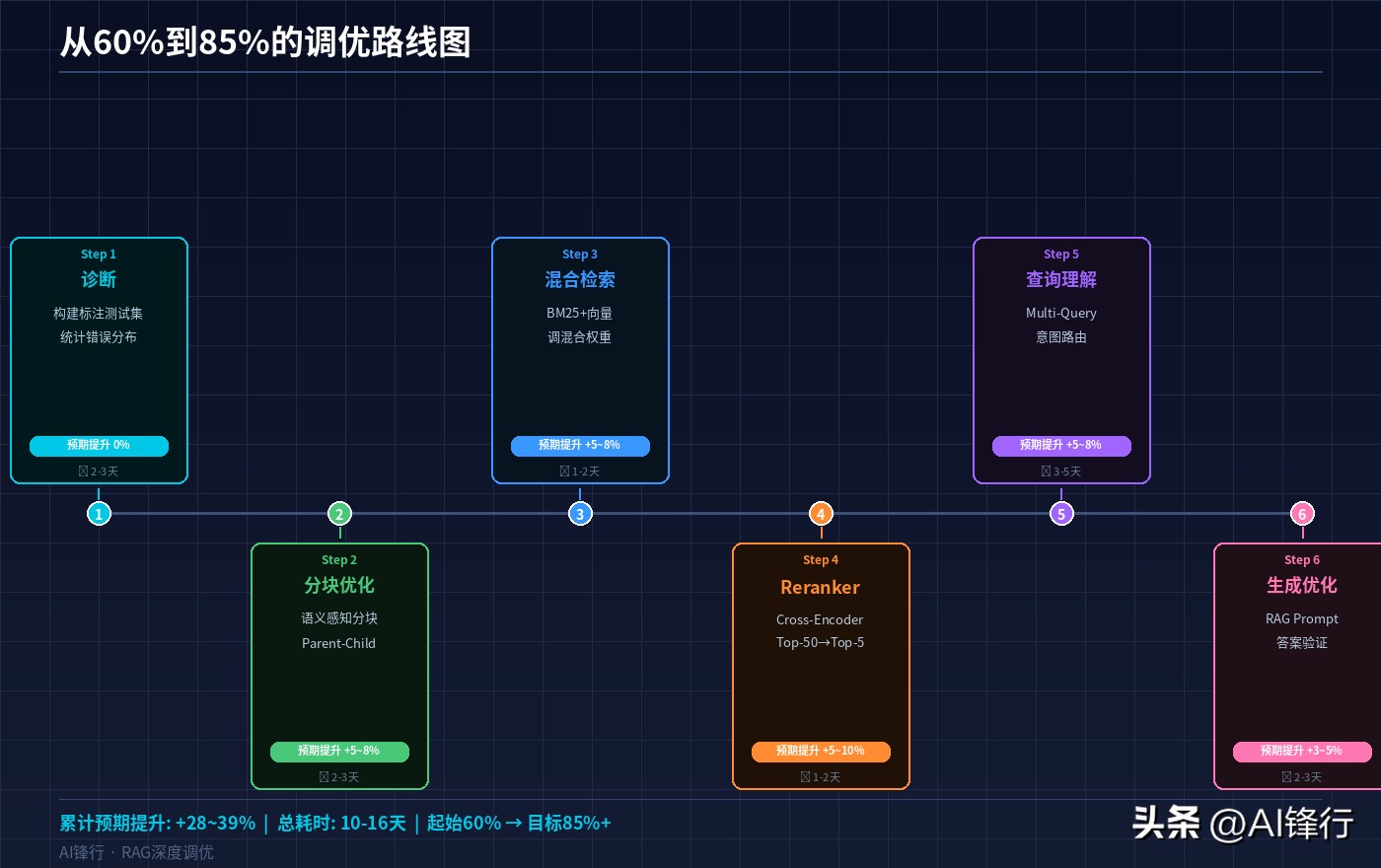
最后给一张可执行的路线图。按优先级排序,每一步都标注了预期提升幅度和实施难度:
第一步:诊断(0%提升,但决定后面所有优化方向)
- 构建200-500条标注测试集
- 统计错误分布:未召回/召回未命中/生成错误
- 预期耗时:2-3天
第二步:分块优化(+5-8%)
- 从固定分块切换到语义感知分块
- 尝试Parent-Child Chunking
- 预期耗时:2-3天
第三步:混合检索(+5-8%)
- 加入BM25关键词检索
- 调整向量/关键词混合权重
- 预期耗时:1-2天
第四步:Reranker(+5-10%,投入产出比最高)
- 接入Cross-Encoder Reranker
- 调整检索Top-K和重排后截断数
- 预期耗时:1-2天
第五步:查询理解(+5-8%)
- 实现Multi-Query查询扩展
- 增加意图识别层
- 预期耗时:3-5天
第六步:生成优化(+3-5%)
- 优化RAG专用Prompt
- 加入答案验证层
- 预期耗时:2-3天
按这个路线图执行,累计提升预期在28-39个百分点。如果起始是60%,优化后达到85%以上是完全可实现的目标。
RAG不是一个"用了向量数据库就完事"的简单系统。它是检索工程、语言模型、评估体系三者的交汇点。60%到85%的跃迁,本质上是从"Demo级RAG"到"生产级RAG"的跨越——需要的不是某一个银弹,而是一套系统性的工程方法论。




发表评论 取消回复