当Google Research发布TurboQuant算法,宣称将LLM的KV缓存压缩至3比特且零精度损失时,华尔街用SanDisk5%的股价下跌给出了第一反应。但很少有人意识到,这场技术突破真正改写的,不是内存的需求总量,而是AI算力的分配规则。我们到底该如何理解这场算法革命的深远影响?
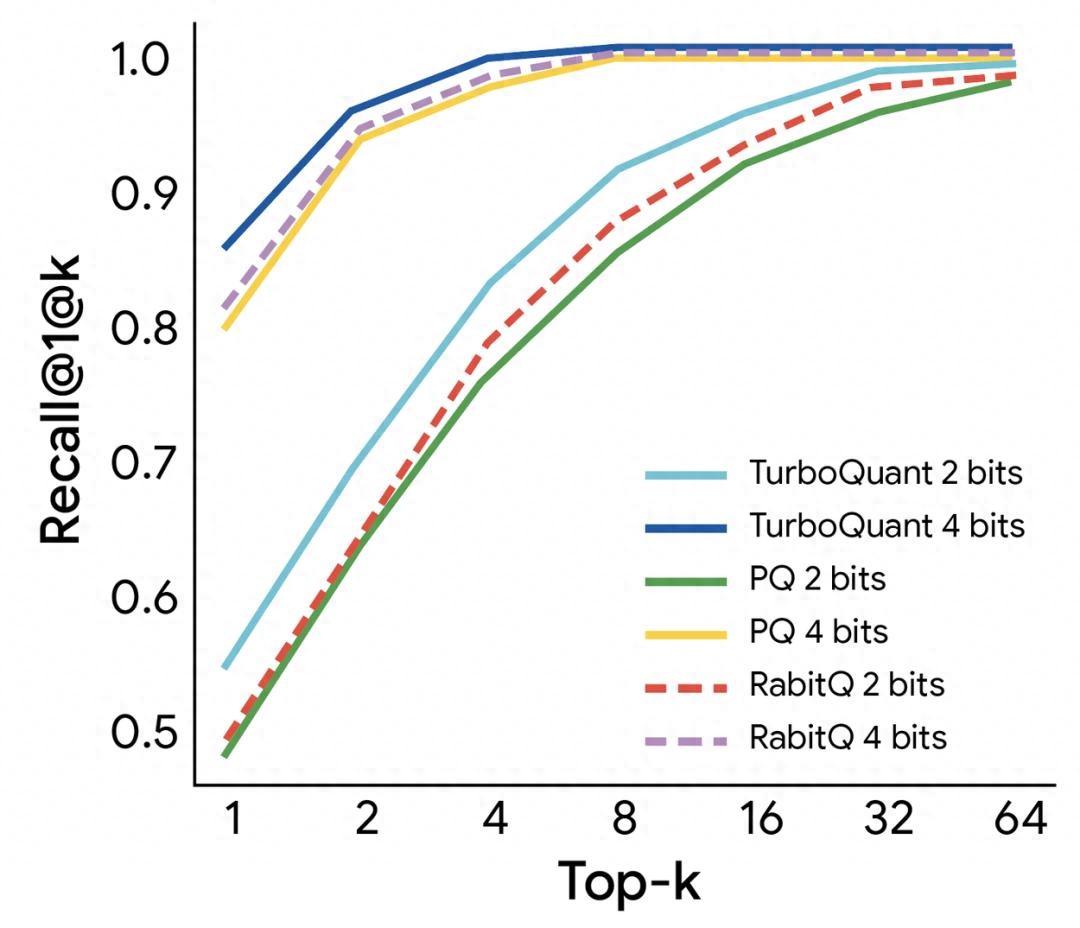
折线对比图 / 不同量化方法在Top-k下的Recall@1@k表现对比
从技术细节到成本核心:KV缓存的隐形战争
在LLM的运行逻辑里,KV缓存一直是个“隐形的吞金兽”。以Llama 3 70B模型为例,512个并发请求、2048token的上下文窗口,就需要512GB的KV缓存空间,是模型权重本身的4倍。对于AI服务商来说,这早已不是技术细节,而是决定盈利空间的成本核心。
传统量化方法的尴尬在于“边压缩边返还”:为保证精度,每个数据块都要存储全精度的量化常数,额外开销抵消了近一半压缩收益。
TurboQuant的突破,恰恰瞄准了这个行业痛点。它通过极坐标变换+量化JL变换的组合拳,彻底消除了量化常数的额外开销,将压缩比从行业基线的2.6倍直接拉到6倍以上,还能在“大海捞针”测试中取得与全精度缓存完全一致的成绩。
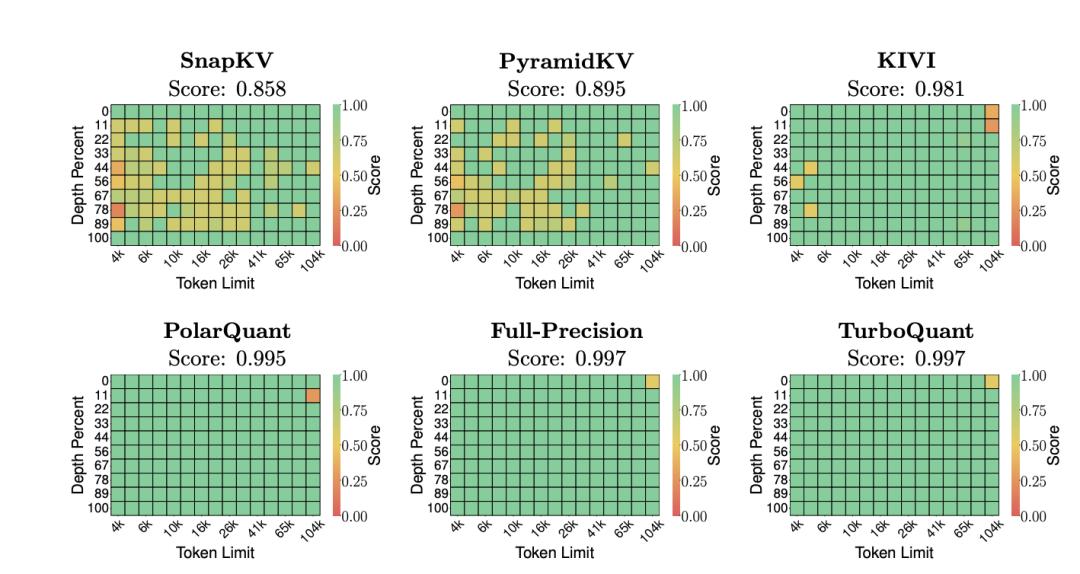
热力对比图 / 多种KV缓存压缩方法的得分热力图对比
资本市场的误读:不是需求消失,而是结构重构
SanDisk股价的5%下跌,本质是资本市场对“AI内存需求见顶”的焦虑。但这种焦虑显然忽略了AI行业的“内存帕金森定律”:每一次硬件升级或软件优化释放的余量,都会迅速被更长的上下文窗口、更多的并发请求、更复杂的模型架构填满。
TurboQuant节省的不是内存,而是把算力从“存储”转向“计算”的可能性。
当KV缓存的内存压力缓解,AI服务商不会减少内存采购,反而会用省下来的空间部署更大的模型、服务更多的用户,或者探索更长上下文的应用场景。对于内存厂商来说,真正的挑战不是需求减少,而是如何跟上AI算力结构变化的节奏——从单纯的容量竞争,转向与算法优化协同的技术竞争。

论文标题及作者信息 / TurboQuant论文的标题、作者及所属机构信息
AI效率革命的起点:从硬件竞赛到算法协同
TurboQuant的意义,远不止于KV缓存的压缩。它标志着AI效率革命的重心,正在从“堆硬件”转向“算法与硬件的协同优化”。
与英伟达的KVTC相比,TurboQuant走的是“实时计算压缩”路线,而KVTC更侧重于“存储传输压缩”,两者其实是互补而非竞争关系。未来的AI推理架构,很可能是多种压缩技术的组合:用TurboQuant优化实时计算路径,用KVTC优化存储传输环节,形成全链路的效率提升。
真正的行业变局,是AI效率的提升不再依赖单一技术突破,而是形成“算法创新-硬件适配-场景拓展”的正向循环。
当算法能把硬件的潜力榨干到极致,AI的应用边界会被迅速拓宽——那些因为成本过高无法落地的场景,比如实时多模态推理、超大规模向量搜索,都将迎来商业化的可能。
未来的悬念:从实验室到产业的最后一公里
尽管TurboQuant的实验数据亮眼,但它距离真正的产业落地还有两道坎:一是在70B以上大模型上的验证,二是与主流推理框架的集成。目前谷歌尚未公布官方代码实现,社区的第三方尝试还处于早期阶段。
技术从实验室到产业的距离,往往比论文到发布的时间更长。
但不可否认的是,TurboQuant已经为AI效率革命指明了方向:通过算法创新突破硬件瓶颈,用数学优化释放算力潜力。对于整个AI行业来说,这不仅是一次技术突破,更是一次认知升级——原来AI的未来,不全在芯片的制程里,也在算法的方程式中。
当我们讨论TurboQuant的影响时,更应该思考的是:在AI效率革命的浪潮中,哪些公司能从“硬件供应商”升级为“效率解决方案提供商”,哪些玩家又会在这场算法与硬件的协同竞赛中掉队?毕竟,真正决定AI行业格局的,从来都不是单一技术的领先,而是对效率革命的全链路理解。




发表评论 取消回复