2026年3月31日,OpenAI宣布完成新一轮融资,同时披露了一个重要数据:用户每分钟调用API接口的Token量超过了150亿,这样计算下来一天是21.6万亿。1
刚好在几天前,中国国家数据局公布,中国日均Token调用量突破140万亿,两年增长1400倍。2
Token是什么?简单说,它是AI处理和生成信息的基本单位——你向AI提一个问题,消耗一些Token;AI给你一个回答,生成一些Token。一个Token大约对应一到两个汉字,具体因模型而异。
为什么要关注Token?因为它让AI变成了一种可以计量、定价和交易的资源——就像“千瓦时”让电力有了价格,“桶”让石油有了期货市场。有了Token,AI经济就有了可以算账的单位。围绕这个单位,目前也正在形成一套全新的经济逻辑:有价格、有供需、有产业链、有国际竞争、有待解决的制度难题。
这就是Token经济学要讨论的事。而以下七个问题,试图为这个正在成型的新经济体系画一张地图。
Token经济学的产业背景
Token经济学不是凭空冒出来的学术概念,它有一个很具体的产业背景。
2026年3月,英伟达CEO黄仁勋在GTC大会前发表了一篇署名文章,标题叫AI Is a Five-Layer Cake(《AI是一个五层蛋糕》)。他把AI产业拆成五层:能源、芯片、基础设施、模型、应用。前三层合起来叫AI工厂,核心功能是制造智能。3后两层中,模型层是智能的载体,应用层让智能发挥价值。
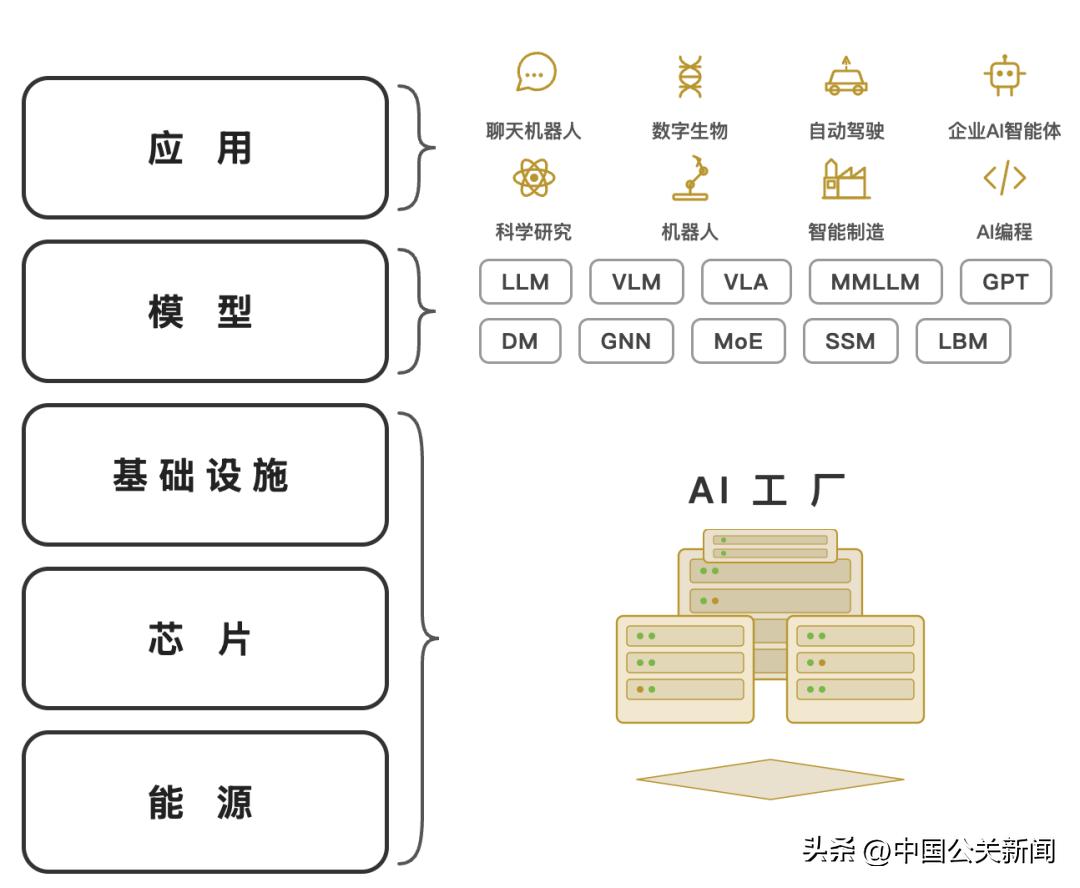
来源:英伟达官方博客,Jensen Huang署名文章(2026.3.10),笔者翻译绘制。
贯穿五层的统一计量单位就是Token,英伟达对Token的定义是:Token是现代AI(生成式AI)的基本单位,也是AI的语言和货币。4AI工厂的关键经营指标——吞吐量、单位成本、每瓦产出、每兆瓦收入——全部围绕Token展开。
五层蛋糕回答的是在产业链中哪里能赚到钱,Token概念回答的是这个产业用什么单位来计算效率、成本和收入。这些概念合在一起,构成了AI产业经济的分析框架。
需要说明的是,这里说的Token本质是AI计算和服务交付的计量单位,不是指区块链上的可交易资产,所以Token经济也不是加密货币世界的Tokenomics。
Q1. 全球一天消耗多少Token?
我们先看一组数字,建立量级感。
OpenAI的API每分钟处理150亿Token,折算一天约21.6万亿。
谷歌2025年9月披露,Gemini每月处理1300万亿Token,日均约43万亿。
而中国国家数据局2026年3月的数字是:日均140万亿——大致相当于OpenAI和谷歌之和的三倍。
两年前,中国的日均Token调用量还只有1000亿。两年,翻了1400倍。
140万亿Token是什么概念?粗略折算,相当于每天生成约2000亿篇千字文章。全中国14亿人,人均每天"消费"上百篇AI生成的千字内容。当然实际不是这么算的——大量Token消耗来自企业级API调用、智能体运行和模型间交互——但这个量级本身就说明问题。
摩根大通预测,中国AI推理Token消耗将从2025年的约10千万亿增长到2030年的3900千万亿,五年再涨370倍。5
我们现在看到的,可能只是开胃菜。
Q2. 一个Token能创造多大的价值?
并非所有Token生而平等。
同样一个Token,用来闲聊的,百万个值0.01美元,用来写代码值200美元,用来做法律文档审阅的,值1000美元,价值差了十万倍。
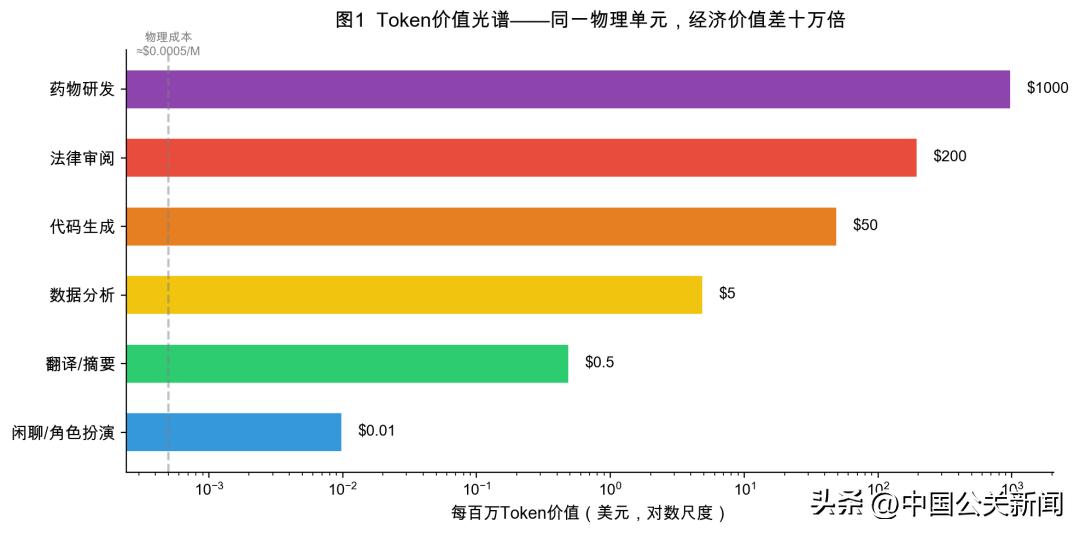
数据来源:Litowitz et al. (2026);Bergemann et al. (2025);各厂商API定价页。
为什么?因为Token有一种此前生产要素不具备的属性:可编程性。同一个底层模型,接收不同的prompt,可以变成翻译、程序员、律师、科学家——直接产出不同价值的智力成果。钢铁做不到这一点,石油做不到,甚至电力也做不到。没有任何一种传统生产要素,能仅凭"指令不同"就改变自身价值百千倍。
耶鲁大学Cowles基金会的Bergemann等人精确地捕捉到了这个特征:Token是可合同化的计量单位——数量可精确计量,但价值完全取决于它被编程做什么。6这产生了一个反直觉的现象:不到5%的Token消耗,创造了超过80%的可测量价值。
所谓平均Token价格,就像用平均房价来描述一个既有茅草屋又有摩天楼的城市——数字正确,但毫无意义。
这种价值分层已经体现在宏观数据中。Collis和Brynjolfsson(2025)估算,生成式AI在2024年仅为美国消费者创造的消费者剩余就高达约970亿美元——用户从AI中获得的价值,远超过他们实际支付的金额。7而这些剩余价值,绝大部分集中在高价值应用场景。
理解这一点至关重要。Token的价值不取决于它的生产成本,而取决于它被用来做什么。这是理解后面所有问题的前提。
Q3. 生产一个Token要花多少钱?
生产一个Token的价格是不同的,取决于你用什么模型、做什么任务。
用轻量模型处理简单问题,比如GPT-4o-mini回答一句闲聊,消耗掉的电力约为0.03瓦时——比LED灯泡亮一秒钟还少。而用最强的推理模型做深度分析,比如GPT-5处理一个复杂的科学问题,,能耗可以高达18瓦时——是轻量模型的600倍。也就是说,同一家公司的不同模型之间,生产Token的成本就能差出几百倍。
为什么差这么多呢?三个因素:一是模型大小,参数越多,生成每一个Token需要的计算量越大;二是任务复杂度,新一代推理模型在输出每一个可见Token之前,会在内部进行大量隐式推演,相当于想了几十步才说一个字。用户看到一个Token,模型内部可能已经生产了上百个。单个可见Token的成本,被思考过程成倍放大了。也就是说,光是生产端,同一家公司不同模型之间的Token成本,就能差出几百倍。
但总体趋势是清晰的:Token在飞速变便宜。
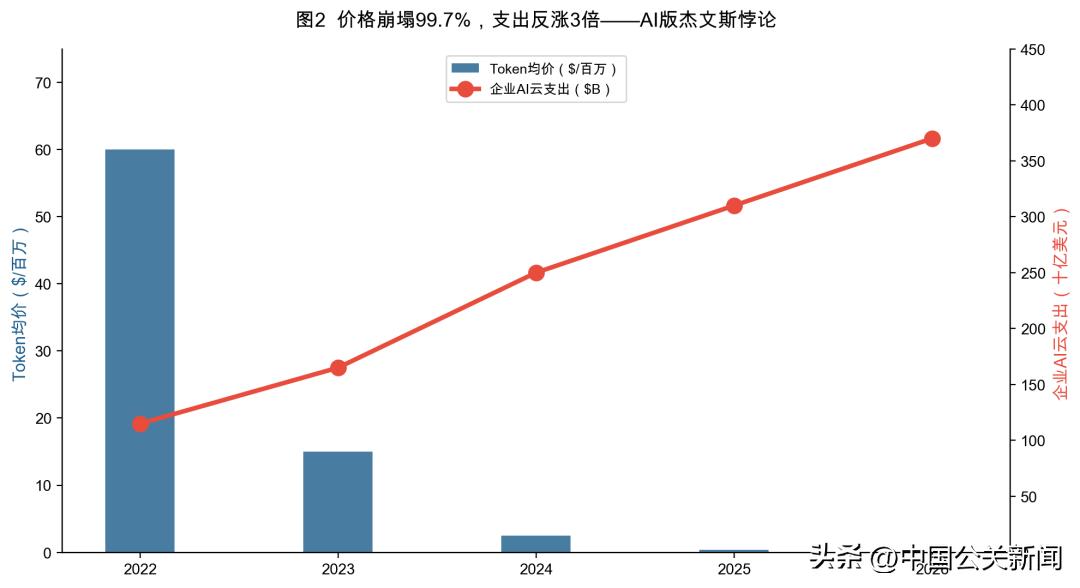
数据来源:Epoch AI (2025);NavyaAI (2026);Tom's Hardware / 罗德岛大学AI实验室 (2025);各厂商API定价页。
2022年,调用GPT-3级别模型需要60美元/百万Token。到2026年初,同等能力的开源模型只要0.06美元——降了99.9%。驱动降价的是三股力量的相乘效应:硬件效率每年提升2-3倍,算法效率每年提升2-3倍,系统优化每年再提升2-4倍。三者相乘,Token成本每年下降5-10倍。同样规模的模型,从上一代GPU换到新一代,每个Token的能耗就能下降约10倍。
但这里有一个反直觉的事实:Token越便宜,全世界在Token上花的钱反而越多。
2022-2026年间Token单价降了99.9%,但同期全球企业AI云支出从115亿美元涨到了370亿美元,翻了三倍多。为什么降价却没省钱?经济学家对此不会感到意外——这是经典的杰文斯悖论:当一种资源的使用效率大幅提升,总消耗量不降反升,正如蒸汽机效率提升后,煤炭消耗不降反升一样。Token价格的下降,将原本被成本约束抑制的潜在需求大规模释放出来。当Token价格是60美元/百万时,只有金融分析、药物发现这些最高价值的任务用得起。当价格降到0.06美元时,代码审查、实时客服、个性化教育、甚至AI角色扮演都变得经济可行了。每个新场景都是新的Token消耗。
而且故事还有更深一层:单个Token的生产成本在持续下降,但单个答案的成本可能在上升——因为更好的答案需要调用更多Token、更大的模型、更深的推理。用户买的不是Token,是答案。所以更好的答案消耗更多的Token,也消耗更多的电。
Q4. 为什么突然全世界的Token都不够用了?
在第一个问题中我们看到了Token消耗的疯狂增长——中国两年增长1400倍。但增速背后还有一个拐点:就是从人用AI,到AI自己用AI。
过去两年,Token需求增长主要靠两个驱动力:一是C端用户习惯养成,比如ChatGPT和元宝等成为日常工具,二是企业把大模型嵌入业务流程,比如客服、代码审查和数据分析等。但这两个驱动力都有一个共同的天花板——人脑。人一天能读多少字,能处理多少信息是有上限的。无论AI多便宜,人的注意力和带宽是固定的。
2025年底开始,一种叫智能体(Agent)的新东西改变了这个格局。
智能体不是聊天机器人——它是能自主执行任务的AI程序。你给它一个目标,比如帮我订最便宜的机票,它自己去搜索、比较、填表、付款。整个过程中,它在不断调用大模型、消耗Token,完全不需要人类注意力参与。
一个企业部署1000个智能体,每个智能体每天消耗100万Token,一年就是3650亿Token。这相当于一个中等国家所有人类用户的总消耗量。8
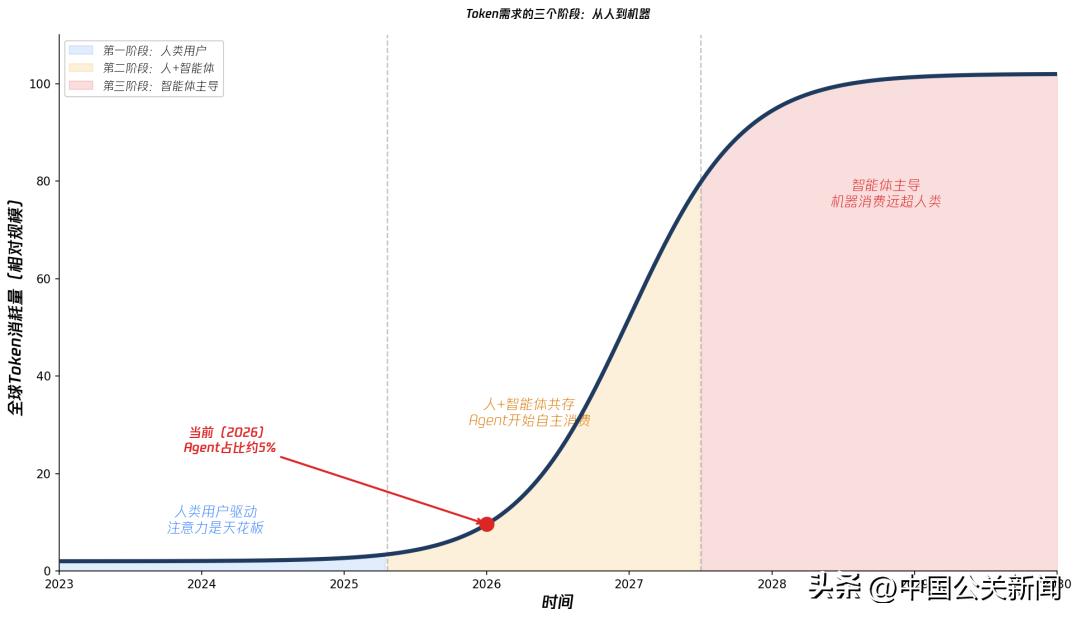
数据来源:Stanford HAI (2025);Jones, C.I. (2026);Anthropic/OpenAI产品发布。
图中三个阶段:人类用户驱动(注意力为天花板)→ 人+智能体共存 → 智能体主导(机器消费远超人类)。红点为当前位置。
更值得关注的是,智能体不只消耗Token——已经有实验项目让智能体拥有自己的账户,自主接任务、赚收入、再用收入购买更多Token。AI正在从工具变成经济主体。
这带来了全新的问题:智能体的收入算谁的?它签的合同有没有法律效力?它造成的损失谁来承担?9
Token需求的下一波暴涨,不再来自人类用得更多,而来自机器自己开始消费。
这些新的模式其实已经在浮现,智能体越来越多的落地和应用,也解释了为什么突然间全世界的Token都不够用了。
Q5. 中国的Token和美国的有什么不一样?
2026年初,一件事让硅谷措手不及:在OpenRouter上,中国模型的Token调用份额已经超过60%。DeepSeek、Kimi、Qwen系列在性价比排行榜上碾压了大量美国竞品。




发表评论 取消回复